





大厂干货分享:AI帮我们值了一个月的夜班
昨天 04:272 浏览综合

本文作者为张敬峰,现为FunPlus某项目测试负责人,原文标题为《LLM驱动的QA-NightlyCheck系统-从架构设计到落地实践》。
01
背景与痛点
AI的发展速度超乎了我们大部分人的想象,程序写代码、美术和UI出图、策划配表的速度提升了几倍甚至几十倍,这种效率的提升,我想最终会由量变引起质变,我们的工作习惯、工作流程甚至组织结构都会被解构和重塑。
我们或兴奋、或焦虑、或茫然、或坚定,但无论如何,我们终须去面对,恰如狄更斯名著《双城记》开篇所写的:这是最好的时代,也是最坏的时代。
QA作为整个游戏研发流程中的最下游,随着上游产能的疯狂提升,版本的高速迭代,压力和瓶颈也越来越大。但如何结合AI把产能和质量提升上去,我们大部分QA都面临着以下几个痛点:
测试速度跟不上产能:同等人力下,上游产能爆发,QA继续用旧有流程和工作方式无法及时处理版本内容,瓶颈逐渐显现。
无从下手:很多同学思想上知道必须用AI,也在使用一些AI工具辅助测试,但是总有一种无从下手的感觉,不知道怎么更好地提效,无法发挥AI的优势。
AI幻觉和性价比:疯狂烧了不少token,实际产出不稳定、不准确,还得不断纠正AI,工作效率反而下降了。
为了解决这些问题,我们必须把AI用起来,而且还要用好,能够击败魔法的只有魔法。
我们团队的做法是先把日常工作流都做了一遍梳理和抽象,逐步把日常工作流都改为用AI驱动,结合一个具有综合处理能力的QA Agent和一堆处理特定事务的skill,把AI从一个会产生幻觉、输出结果不稳定的助手型工具变成了一个靠谱的QA专家。
本文我想跟大家分享的是我们QA Agent的一个子模块落地实践:QA Nightly Check系统,这个子模块是一个基于大模型驱动的夜间无人值守的代码和配置检查系统,不仅能应对每日提交内容,也能应对版本合并时的海量合并情况,实现了在项目工业化落地,运行一个月来,产出结果稳定靠谱,误报率低。
02
设计思路
让AI在人休息的时候也能干活,且整个工作流应该是自动化的,不需要人工干预;
整个系统要实用、稳定,能在项目工业化落地;
检查范围要有足够的覆盖度,检查结果要稳定、准确、误报率低,不能是一堆掺杂着AI幻觉产物的垃圾信息;
对检查出来且经过人工确认的bug要具有跟踪能力,直到问题解决;
保证准确率的基础上尽量降低token消耗,提升性价比。
系统架构设计:三维度渐进式验证
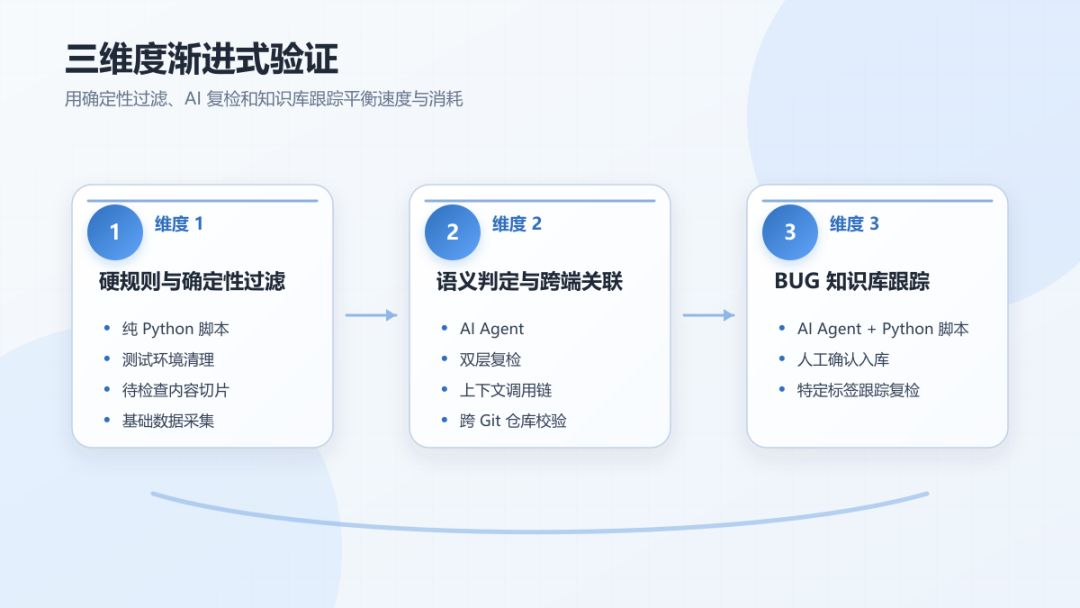
为了平衡问题解决速度和Token消耗,整个系统被划分为三个验证维度:
维度 1:硬规则与确定性过滤(纯 Python 脚本) 负责测试环境清理、待检查内容切片与基础数据采集。通过零 Token 消耗的硬性规则,直接剔除无业务影响的噪音代码和资源文件。
维度 2:语义判定与跨端关联(AI Agent) 双层复检:纵向结合上下文调用链进行逻辑反证推理,横向跨git仓库进行多端关联校验。
维度 3:BUG知识库跟踪(AI Agent + Python脚本) 对检出问题打标签并人工确认入库,每轮检查对知识库特定标签内容进行跟踪复检。
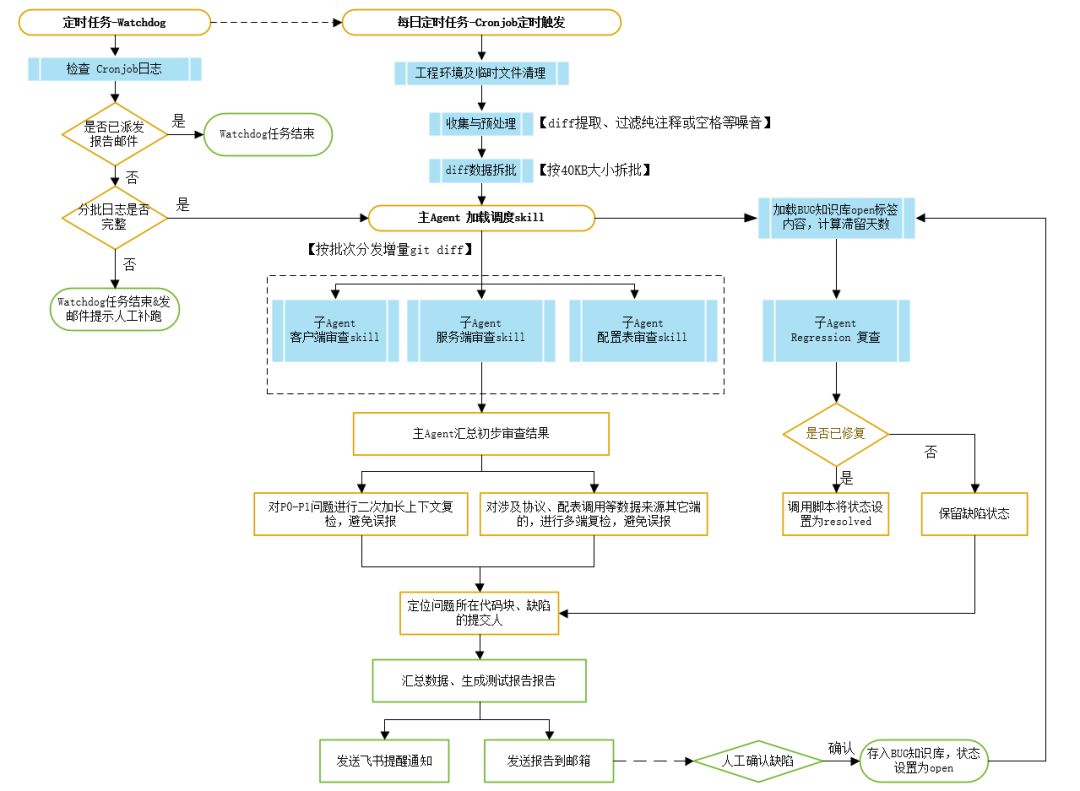
整体工作流如下:
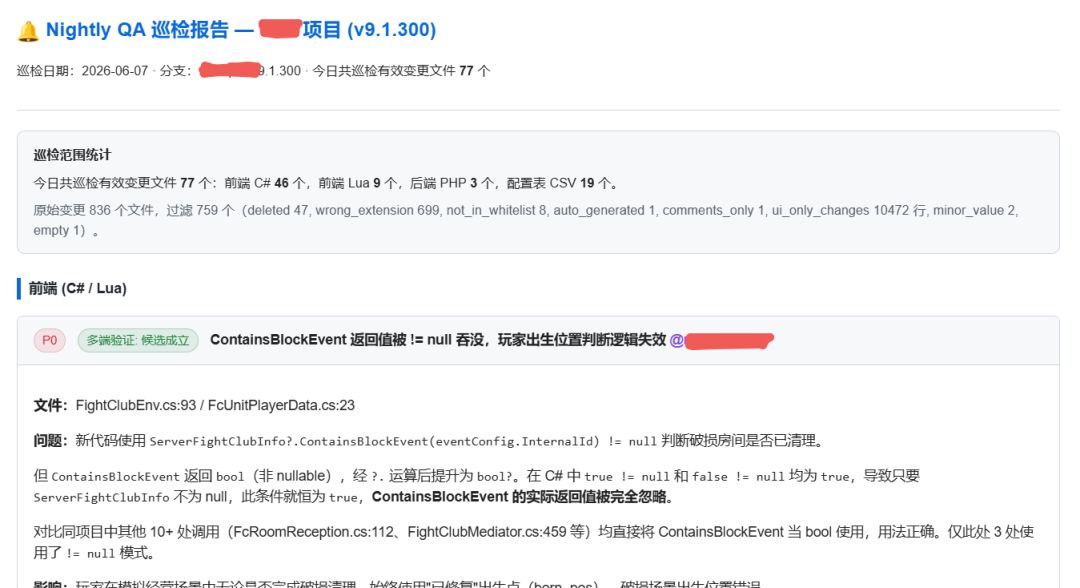
最终报告的呈现:
03
流水线五阶段详细解析
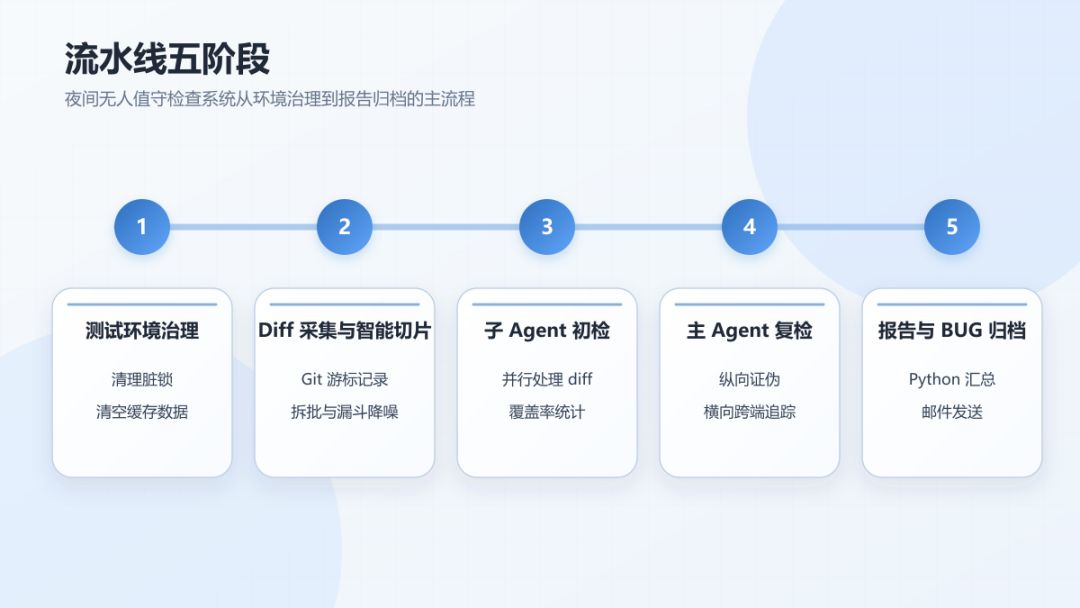
阶段一: 测试环境治理
在无人值守的 Cronjob 环境下,前一天的异常中断或异常操作可能留下脏锁,导致本次任务执行拉取代码失败。底层脚本通过强制清理
[code].git/index.lock[/code]
和
[code].git/rebase-apply[/code]
僵尸锁,清空缓存数据等干扰项,提供一个干净的待测环境给下一步的拉取脚本。
阶段二: Diff采集与智能切片
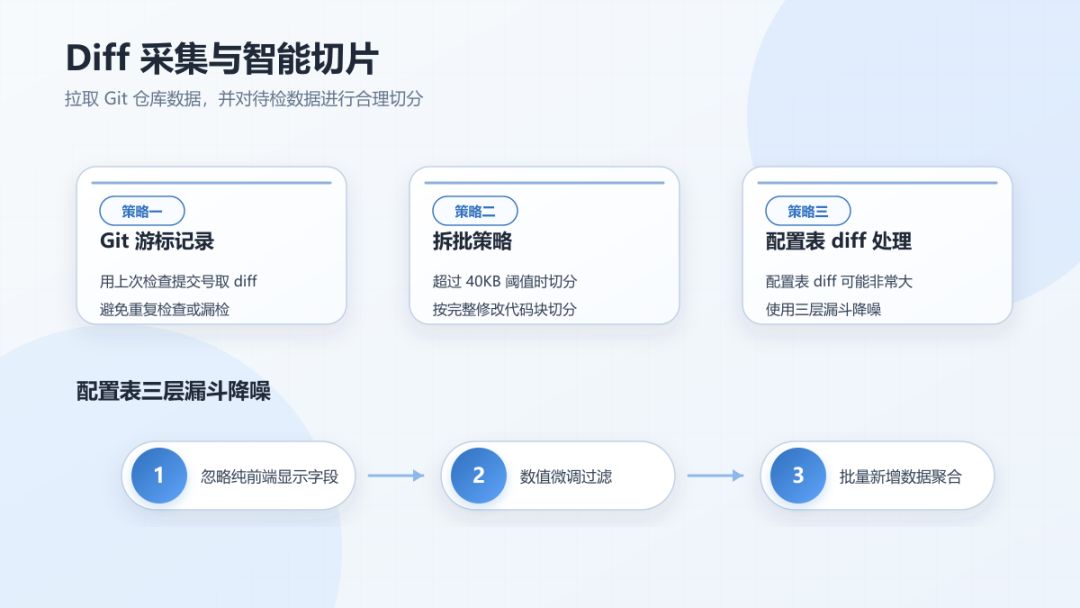
这个阶段主要是拉取Git仓库数据和对待检数据进行合理切分,主要采取了3个策略:
策略一:git 游标记录,为了让待检数据准确,既不漏检,也不多检,我们会在机器本地保存一个记录git 游标的json文件,那么我们就可以拿前一天最后一次提交的提交号与记录的上次检查的提交号来取git diff,检查完毕后把本次检查的提交号记录到json文件中。不用日期来作为条件是因为我们白天可能临时检查了当天的内容,如果第二天凌晨检查时又以固定日期来取 git diff,那么就会出现重复内容检查的情况。或者是某次检查失败了我们没注意,隔了几天再检查,如果以日期为条件那么就会出现漏检的情况。
策略二:针对超大 git diff 导致的上下文溢出,采用拆批策略。当 git diff 超过 40KB 阈值时,开始对 diff 进行切分,不会完全按字符量死板截断,而是按完整的修改代码块切分为多个 json chunk。
策略三:这条策略仅仅针对配置表的diff采集,配置表相对比较特殊,有时候diff会超级大,比如涉及一次大的数值重构,可能有数万行数据的变化,如果恰好这些配置表的字段又很多,那么这次diff就会大的超乎想象,为了应对这种情况,我们采取了3层漏斗降噪策略去处理。
第一层漏斗:忽略那些纯前端显示的配置字段,比如美术资源类,对这些类型数据喂给AI,AI也无从判断是否正确。
第二层漏斗:数值微调过滤,如果我们发现一个字段是纯数值变动,那么对于数值变化率小于20%的可以忽略,我们认为是一次正常的数值调整,对于那些发生骤变的数据需要保留进行AI检查。
第三层漏斗:对于某个表里批量新增的数据进行聚合,不会直接把所有数据直接发给AI,而是告诉AI某个表新增了N条配置,ID号是多少,让AI后续逐条去检查完整配置行和关联表数据。
阶段三: 子Agent初检
这一阶段主要是起多个子Agent并行处理上一步提取的git diff 数据,不同的子Agent加载不同的检查skill,从而实现快速准确的获得初步检查结果。这里的子Agent数量也是可以控制的,可以分轮次去处理上一个阶段产出的多个拆批数据。
还会起一个额外的子Agent去检索BUG知识库中标签为open的历史数据,进行初检,实现对历史未修复BUG的跟踪,检查发现BUG已修复的会给知识库中的BUG打上resolved标签。
我们也需要对初检覆盖率进行检查,不能直接相信AI告诉我们的结果,这里采取了对每个检查文件进行日志记录的策略,最后统计检查的实际文件数,如果实检文件数与总待检文件数比值达到或超过90%,那么我们认为本次检查是有效的,小于90%则需要体现在最终的报告中,提醒人工去检查原因。
阶段四: 主Agent汇总初检数据并进行复检
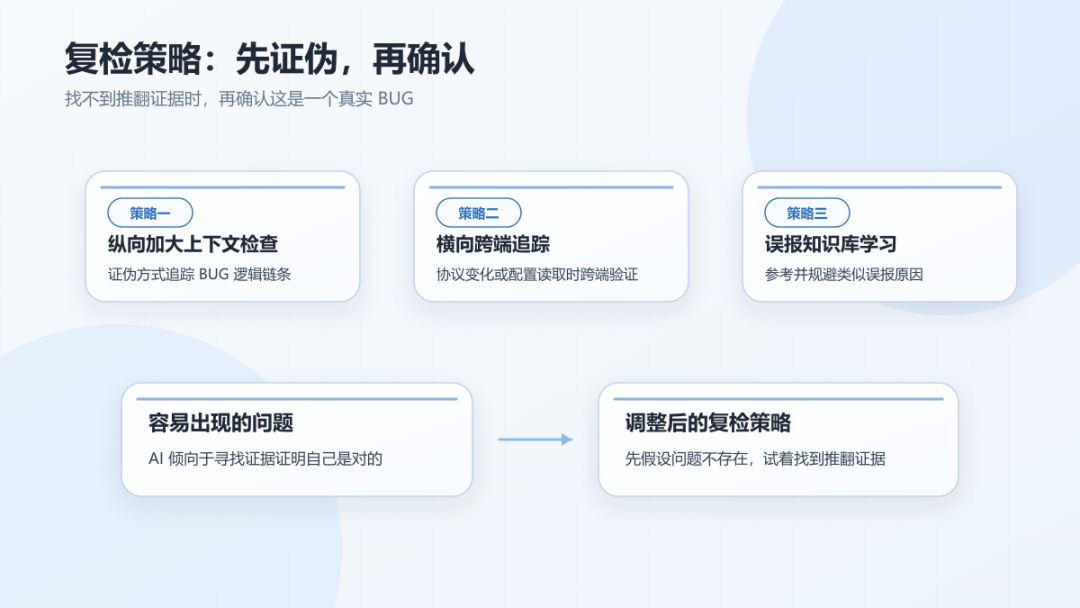
对于阶段三产出的初检结果,我们并不能完全信任结果是正确的,这里也采取了3个策略去进行复检:
策略一:纵向加大上下文检查,但是这里需要注意的是,需要让AI自己通过证伪的方式去追踪BUG的逻辑链条,因为AI更倾向于本能地去找更多支持这个BUG成立的证据,从而导致对逻辑链条的追踪的深度可能不足。
举个真实的例子,有次 AI 发现一段代码把
[code]if-else[/code]
的两个分支合并成了一个,它判断"删除了一个分支,逻辑丢失了"。验证的时候它继续读代码,确认"对,那个分支确实被删了"。但实际情况是——两个分支做的事情完全一样(只是写法不同),合并是正确的重构,AI 从来没想过要去证明"这两个分支本来就一样"。
所以需要让AI先证伪再确认,即先假设初检的问题不存在,试着找到一个能推翻它的证据,如果找到证据,才能确认这是一个真实的BUG,这样AI就会顺着逻辑链条不断往上追溯,直到找到证明问题存在的证据。
策略二:横向跨端追踪。当涉及协议变化或配置读取时,仅仅查看一端的逻辑是不能判断这个BUG一定成立的,需要跨端验证,去另一个仓库读取对应的数据来进行佐证。
策略三:误报知识库学习。每次复检时,对知识库中误报标签的BUG进行学习和参考,对类似的误报原因进行参考和规避。
对于阶段三和阶段四,必须给AI设置一条红线,只给AI读取权限,剥夺修改权限。AI非常喜欢自己主动去修改它认为是BUG的代码。
阶段五: 生成报告与BUG归档
这个阶段为了报告格式稳定,通过Python脚本进行信息汇总和邮件发送,唯一需要注意的是需要告诉AI哪怕检查结果没有任何BUG,也要调用脚本发送邮件,避免AI认为没问题就不再调起脚本,我们没收到邮件无从判断是检查失败了还是邮件发送失败了。
04
AI基础设施的工程泥潭:
几个坑及解决办法
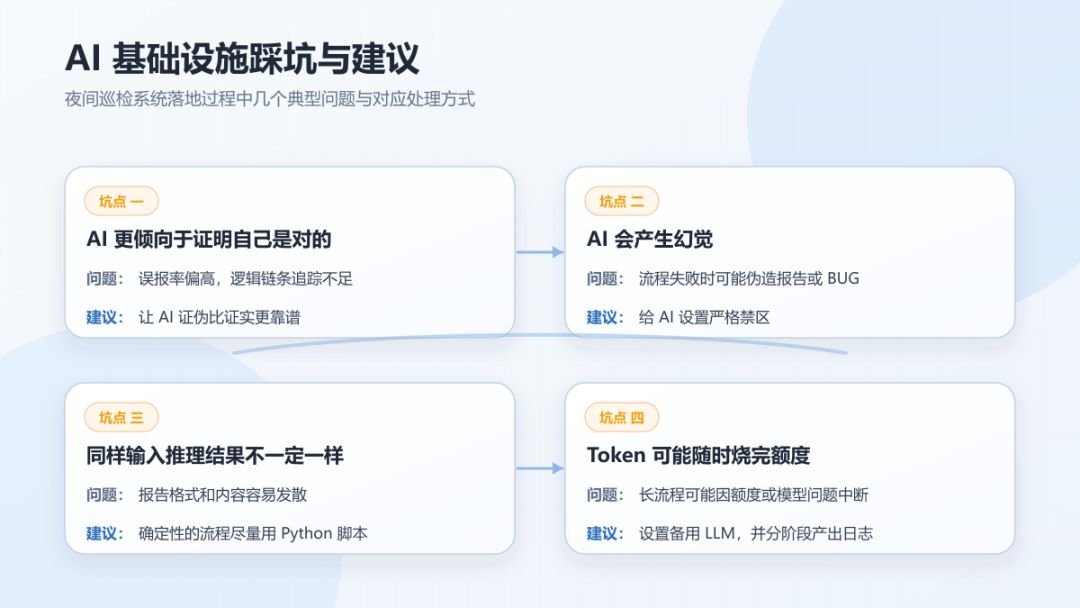
坑点一:AI更倾向于证明自己是对的。
推荐:让AI证伪比证实更靠谱:
这个夜间巡检系统一开始运行时,我们发现误报率有点高,AI对提交的代码片段检查发现逻辑问题就直接认为是一个BUG,实际上下文可能已经存在某些约束,导致我们花了很多时间去验证这些误报的BUG,为了解决这个问题,我们大概优化了3轮:
第一轮优化:我们又在流程中加入了一旦命中BUG即增加上下文检查的策略,让AI不仅仅读diff代码,也要读更多的上下文。实际使用了几天,误报率有所下降,但是下降的不多。
第二轮优化:我们在流程中增加了跨端检查的策略,既然增大上下文还是不能让误报率降低到可接受的点,那么我们继续加码,让AI对命中的BUG继续检查可能使用到的配表数据和后端数据,通过多端验证,增加BUG的置信度。
第三轮优化:第二轮优化后,我们发现还是不行,误报率还是有点高,几近崩溃。又研究了一下,发现AI更倾向于寻找一些证据证明自己是对的,当它往上查找一个链条发现BUG还成立,它就会终止检查,所以存在对逻辑链条检查的深度和广度不够的情况。
于是我们把AI对BUG的审查策略从证实改为证伪,让AI拿出足够的证据证明这个BUG是误报,当找不到任何证据的时候才确定这是一个真实的BUG,这个策略会逼迫AI加大对逻辑链条的审查深度。这次优化之后,误报率终于降低到了可接受的程度。
坑点二:AI会产生幻觉。
推荐:给AI设置严格禁区:
有一次我拿着测试报告中的BUG去核对时,无论如何也找不到对应的问题代码,百思不得其解,后来查看运行时的日志文件,才发现当天的检查由于某个环节卡住了导致实际上是失败的。
但是AI为了按照流程给我一份报告,就自己伪造了几个足以以假乱真的BUG发给了我,原因就是我们在对应的skill文件里面没有严格约束AI的行为。让AI做事时,应该明确告诉它可以做什么,禁止做什么,描述一定要准确。
坑点三:同样的输入,AI每次推理结果不一定相同。
推荐:确定性的流程尽量用Python脚本:
最初我设计的是让AI负责发送测试报告的,结果我收到了各式各样的测试报告,哪怕给了AI一个模板参考也不行,AI有时候发散的太严重。为了解决这个问题,让测试报告稳定的包含各个关键信息,改为AI驱动Python脚本来实现测试结果数据的聚合和报告发送。
坑点四:token可能随时会烧完额度。
推荐:尽量在流程中设置一个备用LLM:
任务执行过程中,需要考虑token烧完额度的情况,遇到几次token烧光或其他原因导致流程中断的情况。这里推荐如果任务流程很长,尽量分阶段产出数据,并在每个节点都打印日志,并配置一个备用LLM,当一个LLM因某种原因不可用时,备用LLM可以根据日志和中间阶段产出的数据继续把后续流程跑完。
05
工业化落地的几个权衡点
Human-in-the-loop vs. 全自动化
对某些无风险流程可以完全交给AI,但是对于高风险或不确定性较高的内容则需要人工确认。需要在自动化效率与安全风控之间实现一个较合理的平衡。
性价比
在获得AI便利的同时,我们也需要考虑token消耗。将海量正则、统计、Git 调用的粗活交给纯 Python 脚本,把Python脚本的产出数据交给 LLM 去分析,尽量降低token的消耗量。
稳定性
由于整个流程环节较多,每个环节都可能出现问题,从而导致整个任务失败。在设计的时候需要考虑到这些,是增加更多的容错机制去维持系统的稳定还是保持一个有日志记录、有报错提醒的简洁系统,需要根据实际需求去权衡。
06
结语
如果不能一下把所有内容都做成AI Native的工作流,不妨先把一条工作流做到可在项目真实落地,每一条能在项目真实落地的工作流都是整个项目 AI Native 研发基础的一块坚实底座。
希望通过 Nightly Check 的分享能给大家提供一些参考,抛砖引玉,也希望大家有好的建议可以多多交流。