






怎样让AI少花你的积分(狗子技巧,2026/3/10)
精华03/10365 浏览开发心得
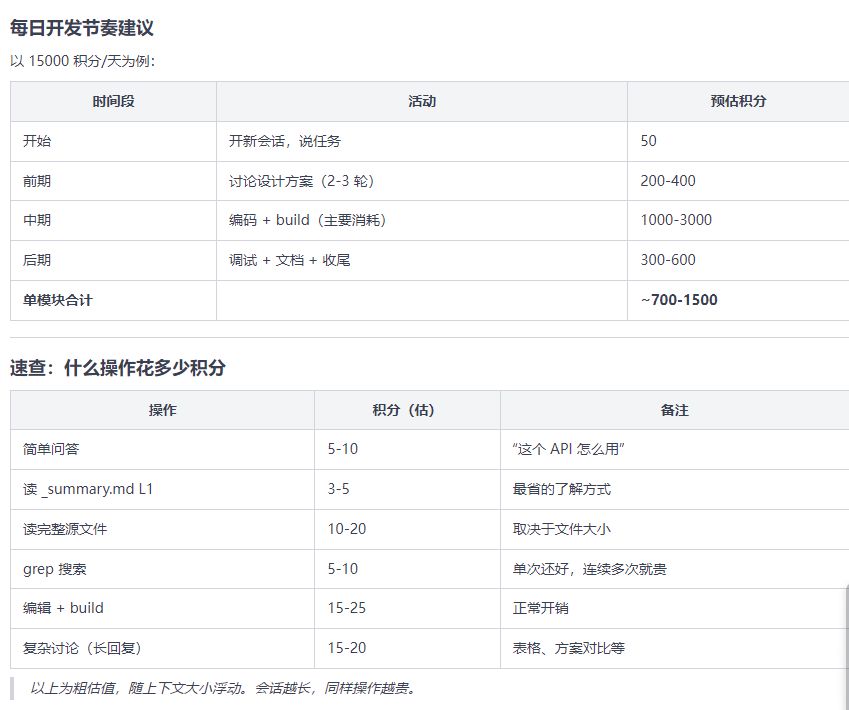
目标:用最少积分完成最多开发。
## 核心概念
- **积分** = 你的每日预算(每天 15000)
- **上下文** = AI 当前会话中"记住"的所有内容(读过的文件、写过的代码、讨论记录)
- 上下文越大 → 每轮对话消耗的积分越多(因为 AI 每次回复都要重新处理全部上下文)
- 所以:**控制上下文大小 = 省积分**
## 省积分的 6 条规则
### 规则 1:一个模块一个会话
**最重要的一条。**
上一个模块的讨论记录、读过的文件、调试过程,对下一个模块毫无用处,但会持续消耗积分。
```
做完映射模块 → 开新会话 → 做机构生成模块
```
**什么时候该开新会话:**
- 当前模块已完成(代码 + build + 文档全部搞定)
- 要切换到一个完全不同的模块
- 感觉对话已经很长了(通常 20+ 轮对话后)
**什么时候不用开新会话:**
- 当前模块还在调试中
- 紧接着要做的小改动和当前模块相关
### 规则 2:_summary.md 渐进式扫描
AI 读代码是按 L1 → L2 → L3 三层递进的:
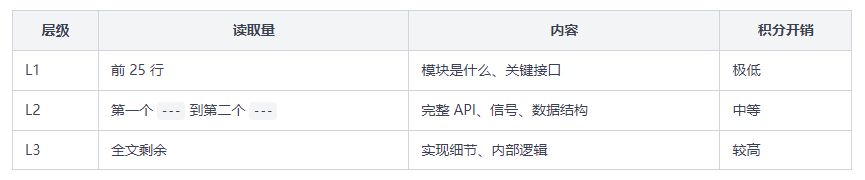
AI 会先扫 L1,只有相关的才继续读 L2/L3。**不相关的模块只花 L1 的积分。**
你能做的:
- 确保每个模块都有 `_summary.md`(AI 自动生成)
- L1 写得好 = AI 能快速判断"要不要深入读"
### 规则 3:紧凑索引代替 grep
grep 一次文件 ≈ 50积分,连续 grep 5 次就很贵了。
**解决方案:把高频查询数据压缩到 _summary.md 里。**
例如:
```
之前:每次遇到不认识的条目 → grep 查文件 → 50积分/次
现在:_summary.md L1 里放了完整索引(20 行)→ 一次性读入 → 0 额外开销
```
你能做的:
- 如果某类数据会被反复查询,让 AI 把索引压进 _summary.md
- 常见格式:`key=真实含义` 一行一组,按类别排列
### 规则 4:指令越具体,积分越省
模糊指令 → AI 要搜索、猜测、多轮确认 → 消耗积分
```
贵: "帮我优化一下代码" → AI 要读所有文件找优化点
便宜:"player.lua 第 50 行的 → AI 直接定位,一轮搞定
跳跃逻辑改成二段跳"
```
你能做的:
- 知道文件名就说文件名
- 知道大概位置就说行号
- 有明确想法就直接说,不要让 AI 猜
### 规则 5:讨论和编码分开
设计讨论(纯文字)比编码(读写文件)便宜#得多。
```
高效流程:
1. 先纯文字讨论方案(省)→ 确认
2. 再一次性编码(该花就花)
3. build 验证
低效流程:
1. 写一半代码 → 发现方向不对 → 推翻重写(浪费)
```
### 规则 6:build 错误贴关键行
如果 build 失败或运行报错:
```
贵: "报错了,帮我看看" → AI 要自己去读日志
便宜:"build 报错: → AI 直接定位问题
main.lua:47: attempt to
index a nil value"
```
你能做的:
- 复制报错的关键信息贴过来
- 如果有截图,截报错部分就够了,不用截全屏
---
---
*最后更新: 2026-03-10*