




托纳姆物语编程系列(6)—— 如何认路?
04/25322 浏览综合
前段时间看到两年前的东西还有人看,就想着再写一点什么,本来再tlm里面做一个自动驾驶来着,但是有点过于花时间了。一是tlm视角太受限,二是我一个人每次重新训练模型很吃力。不过好在我还是基本完成了视觉部分的功能,本文中以前文章提到的东西我就不会在提了,见谅。
1. 什么是实例分割
说这个之前我得让你知道什么是对象检测,放一个图你就明白了。

对象检测识别场景中你感兴趣的目标并输出是一组边界框,这些边界框包围了图像中的目标,以及每个框的类别标签和置信度分数。

实例分割比对象检测更进一步,实例分割可以以不规则的形式勾勒出图像中你感兴趣每个对象,当你需要知道它们的精确形状时,实例分割就是对象检测不可代替的。
前面说过我们的目标是做一个自动驾驶的东西,我的方向就是用YOLOV8实时分割出“可以走的路”。看一张效果图
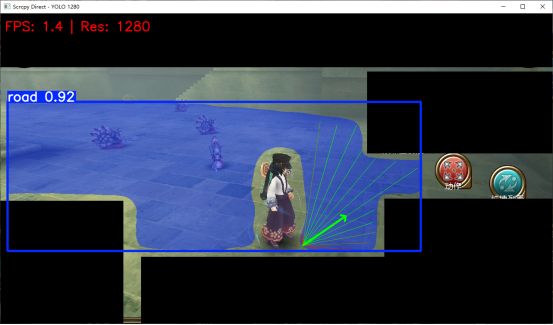
中间角色镂空是因为我再标注的时候担心角色服装,影响识别,就绕开角色,但是有点后悔这样做。黑框是挡住无用信息,防止干扰。
2. 如何快速截图
在说怎么训练之前,我想先解决一个问题,如何实时将手机画面以视频流的方式传到我的电脑进行解析。传统截图的形式最快可能一秒截图六次,作用一个一秒至少30帧的游戏,这个速度确实不让人满意,这个其实也算我很久以前做这个系列的遗留问题,这次花了较多时间解决了这个问题。灵感来自一下这个开源项目。
这个项目其实本身是可以直接使用的,但是,这个库太久没人维护,有些东西已经不能使用了,特别是用来解析视频流的AV库,经过一次破坏性更新,以前的语法都不能用了,但是好在这个项目本身并不复杂核心依附于Scrcpy(安卓投屏的开源项目),我重写了一下。整个项目我会放在一个网盘中。
具体的代码我就不讲了,我讲一下整个代码的逻辑:1.先使用adb将Scrcpy的客户端文件发送到手机里面。2.在使用adb命令将其在手机运行。3.用套接字获取视频流数据。4.用AV库解析视频流成为python可以处理的格式。
3. 模型训练
这部分说起来其实真挺麻烦的。但其实也很简单,就是标注然后训练。
3.1 标注
标注我推荐labelme,安装方式很简单,一行命令就可以搞定,但需要你搞定python环境,你可以去看这个系列的第一篇,和这个系列的差不多最后一篇也讲了如何训练模型。
有了labelme你需要去截图收集素材。有了图片,准备工作就做完了。
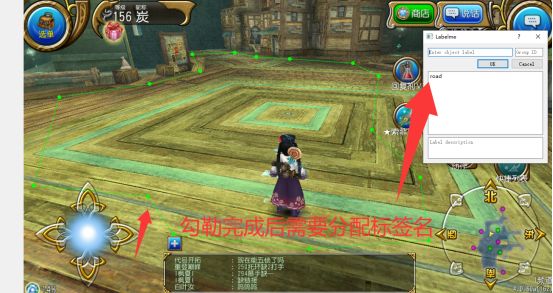
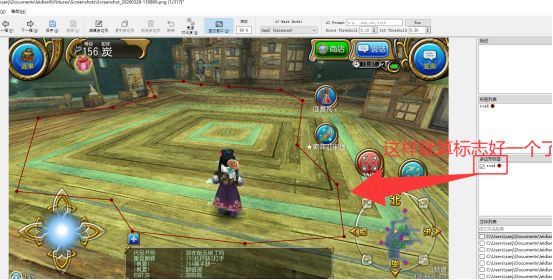
后面就一直重复标注。
3.2 格式转换
Labelme标注后输出的文件是json,但是yolo用的是txt,所有我们需要进行格式转换,这一步也需要使用到python。
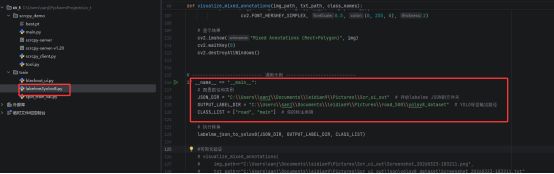
这个程序我也会打包到网盘中。
3.3 训练集组成
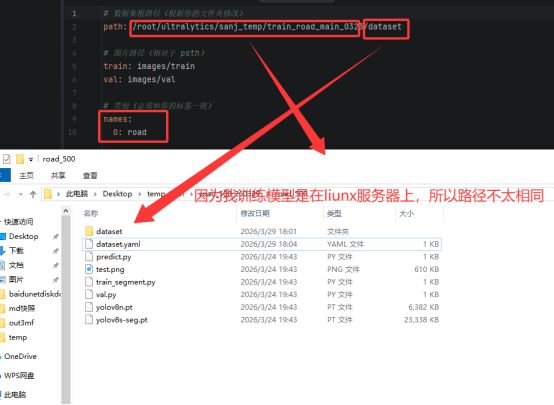
得到txt和图片后,yolo不是你吧这些东西一股脑塞给他,他就能训练的,我们还需要安装他要求的项目文件夹格式分类存放好这些文件。参考如下

我也会将我用的训练文件放到网盘中供你们参考。
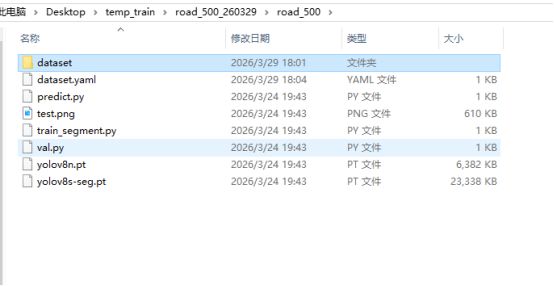
我们知道了这个项目结构不可能我们需要一个一个去建文件夹,然后慢慢复制粘贴吧,所有我也写了一个python程序用来完成这个任务。
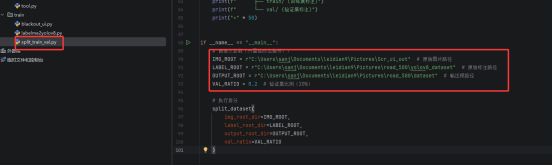
但是有一个文件需要你自己去配置,就是这个后缀为.yaml的文件
说了挺多其实也并不复杂,你可以参考我的项目就可以了。
3.4 运行训练
因为我用的电脑很辣鸡显卡是一个RTX580,而这种模型训练需要用到一个比较好的N卡。但好在现在跑AI的业务很多,你可以在网上直接租用一个云服务器用来跑模型,我用的是AutoDL。
这部分我不太想继续讲了,这些你可以自己去网上找教程试着多尝试一下,可以参考我以前的教程。
4. 主程序
这个我也不讲具体的代码了,逻辑讲一下,这个程序里有我烂尾的后处理内容,就是用来寻路的函数。
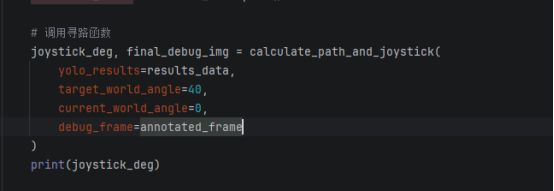
有兴趣你也可以看看,这里要提一点的是,虽然我们使用了视频流的方式得到了一个1秒30帧以上的数据,但是我们的图像处理速度不一定更得上,但是视频流为了保证图像的连贯性会让你没有读到的数据在管道中缓存,这样就导致我们失去了实时监控的效果,因此我使用了一个子流程专用于提取视频流数据,让我们获得的每一张图片都保证是最新的。
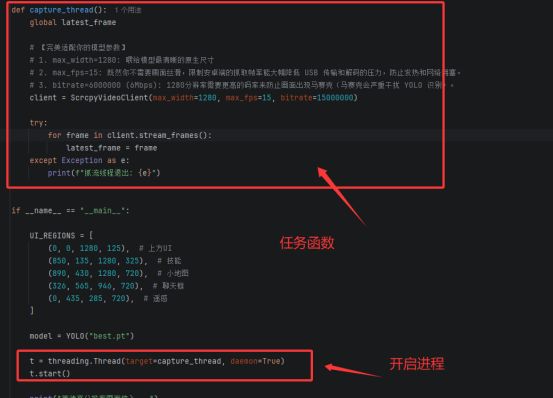
还有一点就是我训练的时候把技能血量这些全部遮挡了起来,这个忘记说了,这一步我也做了一个程序。
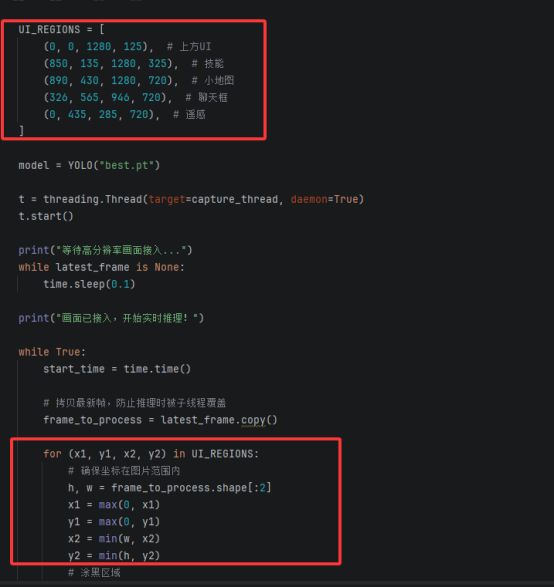
因为训练的时候我们把技能血条这些无用数据遮挡了,所以我们喂给模型识别的时候也尽量将这些无用内容遮挡一下。
5. 总结
这次这一篇说实话,写的没有以前那些那么用心,主要也没以前闲暇时间那么多了,但我觉得应该也差不多而且应该会被封禁。算了不说了,五一在即,祝托友们五一安康,喜乐常伴!!