






自由创作大世界游戏的存档架构:让玩家永远感知不到"在等数据
修改于05/13214 浏览开发心得
类别:游戏架构 / 云存档 / 性能优化(写这个的理由是:常驻服务器的游戏,如果存档在客户端,那么存档永远不会调用,只能存档到客户端向服务器发送请求,过一次才能获取数据。意思就是说,客户端可以兜底,但是如果不在服务器过一次,永远不能调用,那么对于大世界来说,存档可能高达几十M,这样对玩家来说是非常不友好的。)(文中的单KEY30K上限删除,他们说单KEY上限是1M,但是无论多少部妨碍数据分离。)


引言:自由创作游戏的存档困境
想象一个世界:玩家可以在岛上自由铺设地板、放置装饰物,更重要的是——可以给每一件家具、每一个工具亲手画上独一无二的像素图案。这是"像素涂鸦世界"的核心玩法。
但这个玩法带来了一个工程挑战:存档可以变得无限大。
一个玩家可以拥有几十个物品品类,每个品类下十多个零件,每个零件最多三个画作槽位。每幅画是 16×16 的像素画布,用调色板压缩后仍有约 1.4KB。把所有画作打包成一个 JSON 存到云端,一旦玩家认真创作,轻松超过——而这恰好是我们使用的云存档 API 单 Key 的上限。静默失败。数据丢失。玩家重新登录,发现画作没了。这是我们在真实测试中遇到的 Bug,也是本篇文章的起点。
章节核心内容
引言单 Key 超 30KB 的真实 Bug 来源
第一章按变化频率分类数据,找到拆分的依据
第二章三层 Key 架构:world_meta / chunk / drawing
第三章画作增量脏标记写入策略,只上传改过的物品
第四章客户端双写兜底 + 10分钟全量校验,无感修复坏档
第五章登录三级流水线:meta → 玩家脚下区块 → 屏幕内画作 → 全部
第六章上传/下载的主动权:从推模型走向拉模型的路径第七章v3 像素编码原理:48色单字符,256字节/幅结语架构的本质是对"变化频率"的分类

玩家画集合
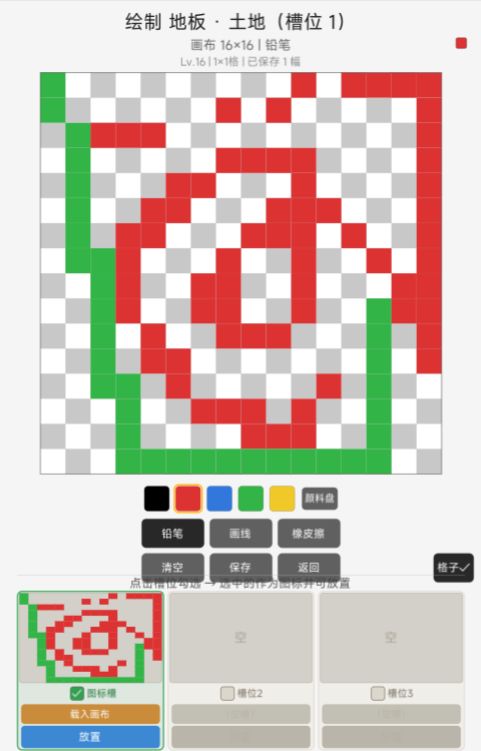
绘制瓦片样式
布置
继续布置存档
第一章:先把问题想清楚
在动手改架构之前,我们梳理了存档数据的性质分类:
数据类型写入触发体积变化频率背包物品捡到/消耗物品< 1 KB
高快捷栏配置玩家手动换< 100 B低玩家位置每次移动< 50 B
高饥饿值每秒衰减< 20 B高地图瓦片建造/破坏地块每区块 ≈8 KB
低装饰物摆放放置/移除装饰每区块可变低画作像素玩家主动保存每物品 ≈13 KB
主动触发观察这张表,我们发现三件事:
- 背包/玩家位置和地图数据绑在一起,是最大的错误。 玩家每次移动、每次吃东西,都会触发整张地图的重新序列化和上传,而地图几乎没变。
- 画作数据是存档里的"大象",但它只在玩家主动保存时才变。 完全没必要和其他数据混在一起。
- 不同数据有不同的"紧迫性":背包丢失会立即影响游戏,画作丢失是更大的情感损失——两者需要不同的保护策略。
第二章:三层 Key 架构我们把全部存档分为三类独立的云端 Key:serverCloud Key 结构
│
├── world_meta ← 背包 + 快捷栏 + 饥饿 + 玩家位置
│ 体积 <2KB,写入节流:30 秒
│
├── world_v1 / chunk_cx_cy ← 地图瓦片 + 装饰物
│ 体积 ≈8KB/区块,写入节流:60 秒
│
└── drawing_<catIdx>_<itemIdx> ← 三槽画作像素
体积 ≈13KB/物品,增量写入:主动保存后 30 秒内刷盘
2.1 world_meta:最轻量,最优先json
复制{
"version": "6.0",
"bag": [{"i": 1, "id": "fish_meat", "n": 5}],
"hotbar": ["fish_meat", null, null, null],
"survival": {"hunger": 87},
"player": {
"tileX": 15, "tileY": 23,
"chunkX": 0, "chunkY": 0
}
}
注意 chunkX/chunkY 是派生值(floor(tileX / 50))。它们存在这里的目的只有一个:登录时拿到 world_meta,立刻知道玩家在哪个区块,发起优先地图请求,一秒都不浪费。30 秒的节流看起来很短,但背包 <2KB 的体积让我们完全可以承受这个频率。背包丢失 30 秒内的进度,远比地图数据丢失代价小。2.2 地图 Key:从单 Key 走向区块化目前的 world_v1 存储整张地图的全部瓦片和装饰。这对于小岛可以接受,但随着玩家的岛越来越大,这个 Key 会越来越胖。我们的设计目标是迁移到 chunk_<cx>_<cy> 的区块格式:每个区块是 50×50 格,地板层用 1 字符/格编码,装饰层用 2 字符/格编码。单个区块 Key 约 8.7KB,在 API 上限内绰绰有余,并且可以按玩家位置优先加载。这是第二阶段的工作,但 world_meta 里已经预先存好了 chunkX/chunkY,接口已经打通。2.3 画作 Key:每个物品一个 Key,三槽合一这是本次架构中最重要的决策,也是最能体现"按数据性质设计"理念的地方。我们为什么不是"每幅画一个 Key"?每个物品最多有 3 个画作槽位,如果每槽一个 Key,60 个物品就需要 180 个 Key。而且会出现"slot1 新、slot2 旧"的状态不一致问题——同一个物品的三个槽本质上是同一件事的三个版本,应该原子地更新。我们为什么不是"所有画作一个 Key"?这正是最初导致 Bug 的方案。超过 7 幅画就超出 30KB 上限,静默失败。最终方案:一个物品一个 Key,三槽合并存储。lua
复制-- Key 命名:drawing_<catIdx>_<itemIdx>
-- Value 结构:
{
s1 = "AAAB...(v3字符串编码,≈1.4KB)",
s2 = "ZZZY...",
s3 = nil, -- 空槽不存,节省体积
updatedAt = 1747123456
}
单 Key 体积:3 槽 × 1.4KB + overhead ≈ 4.5KB,距离 30KB 上限有 85% 的余量。Key 数量:假设 6 个品类 × 10 个物品 = 60 个 Key,比"每槽一 Key"减少 67%。
第三章:画作的增量写入策略传统方案是定时全量写入:每 N 秒把所有画作序列化成一个大 JSON 上传。这对少量画作可以接受,对自由创作游戏是灾难。我们的方案是增量脏标记:lua
复制-- 服务端内存缓存结构
playerDrawingsCache[uid] = {
drawings = { "catIdx_itemIdx" → { s1, s2, s3, updatedAt } },
dirtyItems = { "catIdx_itemIdx" → true }, -- 记录哪些物品被改过
timer = 0,
}
写入流程:
- 玩家在涂鸦本里保存一幅画 → 客户端立即发 DrawingsSave RemoteEvent,携带单幅像素数据
- 服务端收到 → 写入内存缓存,同时在 dirtyItems 里标记这个物品 Key
- 每帧 AutoSave 计时:如果 dirtyItems 非空,累积 30 秒后刷盘
- 刷盘时只写 dirtyItems 里的 Key,其余画作完全不动
- 玩家每次保存只触发一个 Key 的写入,不影响其他物品
- 短时间内频繁保存同一幅画(反复修改),30 秒窗口内会合并为一次写入
- 服务器写入次数与"用户实际改了多少个物品"严格正相关,而不是"总画作数量"
第四章:客户端双写兜底——服务端坏档时的自救云端存储不是 100% 可靠的。网络闪断、API 超时、服务升级都可能导致某次写入失败。对于画作这种玩家投入了大量情感劳动的数据,我们不能只靠云端。双写策略:
- 每次玩家保存画作,客户端同步写一份本地文件 drawings_<uid>.json
- 这份文件只在客户端设备上,不上传,不展示,就是个静默备份
登录时的合并逻辑:登录
↓
1. 先读云端画作(DrawingsSync)
2. 同时读本地缓存文件
3. 对每幅画,比较 updatedAt 时间戳
4. 取较新的版本作为最终状态
5. 如果本地比云端新 → 立即补传到服务器(修复坏档)
这个机制的价值在于无感修复:玩家不需要知道云端数据丢了,登录时系统自动检查、自动修复,比手动回档的体验好得多。此外,我们设计了一个 10 分钟全量校验周期:定时遍历所有画作,比对 updatedAt 与 lastSyncedAt,把有差异的画作重新上传到服务器。这是最后一道防线,确保即使中途有某次 RemoteEvent 丢包,最终数据也是完整的。
第五章:登录时的分优先级加载流水线这是整个架构里用户体验感知最强的部分。用户的期待: 登录游戏,立刻看到自己的角色、背包、岛屿,画作慢一点没关系,但不能空白等待。我们的三级流水线:登录握手完成
│
├─ 第一步(最优先,并行):
│ 加载 world_meta → 恢复背包/位置/饥饿
│ 目的:玩家立刻能操控角色,背包立刻可用
│ 耗时:< 500ms(Key 小,API 快)
│
├─ 第二步(紧接着):
│ 根据 world_meta.player.chunkX/chunkY
│ 优先加载玩家所在区块的 chunk_cx_cy
│ 目的:脚下的土地先渲染出来
│ 耗时:< 1s
│
└─ 第三步(后台异步,不阻塞):
BatchGet 周边 8 个区块
+ BatchGet 屏幕内物品的 drawing_* Key
+ 继续 BatchGet 剩余画作
关键设计点:world_meta 里预存了 chunkX/chunkY,这不是冗余数据,是一个预计算的优化锚点。服务端不需要做任何计算,拿到 world_meta 就知道该先加载哪个区块。涂鸦本的懒加载(类比视口剔除):玩家打开涂鸦本时,并非一次性加载所有分类的所有画作。而是:
- 显示第一个分类,优先请求该分类所有物品的 drawing Key
- 滚动到第二个分类时,再请求第二个分类的 Key
- 已经下载的 Key 缓存在内存中,切换回去不需要再请求
这个逻辑和游戏引擎的"视口剔除"在哲学上是一致的:只处理当前用户能感知到的数据。 差别在于视口剔除是空间维度,这里是"用户交互意图"维度。
第六章:上传与下载的主动权上传(客户端 → 服务器):完全可控每次 SaveCurrentDrawing() 调用只发送当前这一幅画的数据,不触发其他 Key 的写入。未来如果需要更精细的控制(例如低网速时降级为只保存当前正在编辑的物品),可以在 AutoSave 里加优先级队列,按 updatedAt 降序排列待上传的 Key,保证最新修改的画最先到达服务器。下载(服务器 → 客户端):从推模型走向拉模型当前实现是推模型:服务端登录时把所有画作打包推送。这对画作少的玩家足够用,但对重度创作者是个瓶颈。设计中的拉模型:客户端请求:RequestDrawings { keys = ["1_3", "1_5", "2_1"] }
服务端响应:DrawingsBatch { drawings = [{ catIdx=1, itemIdx=3, ... }, ...] }
客户端控制请求的 Key 列表,就能精确控制"先下载哪些画作"。登录时:
- 先请求屏幕内可见的装饰物对应的 drawing Key
- 再请求周边区块内的 drawing Key
- 最后请求涂鸦本里的全部 Key
这样玩家走到哪里,画作就先加载到哪里,永远不需要等一个大包解析完成。
第七章:像素编码——让体积降到极限画作的像素数据是存档中体积最大的部分,因此编码效率直接决定架构可行性。我们经历了三代编码格式:v1(已废弃): 对象数组 {x, y, r, g, b, a},每个有颜色的像素存一个对象。100 个像素 ≈ 2KB,稀疏画作还好,密集画作爆炸。v2(已废弃): 平铺整数数组,每个格子一个调色板索引(0-192,含透明度层)。固定 256 格 × 1-2 byte = 512B 左右。有改进,但包含了已删除的 alpha 通道,冗余数据。v3(当前): 单字符编码 + 48 色固定调色板。
- 每格只用 1 个字符(0 = 空,A-Z = 颜色 1-26,a-v = 颜色 27-48)
- 16×16 画布 = 256 字符 = 256 bytes 原始,JSON 后约 280 bytes
- 三槽合计约 840 bytes,加 overhead 不超过 1.4KB/物品
48 色调色板的选择不是随意的。48 种颜色覆盖了像素画风格的核心色域,对于 16×16 的小尺寸画布,颜色精度和视觉质量的平衡点恰好在这里。RGB 精确值用最近邻匹配算法映射到调色板,保存时无损,加载时完全还原。
语:架构的本质是关于"变化频率"的分类回顾整个设计,所有的优化决策都基于同一个核心判断:不同数据有不同的变化频率,不同的重要性,不同的访问时机。 把它们混在一起,就是在用最高代价应对最低频率的变化。分离存档 Key,是告诉系统"这两份数据的节奏不一样,请分开对待"。
增量脏标记,是告诉系统"只有被改过的数据才需要上传"。
分优先级加载,是告诉系统"玩家当前能看到的比看不到的更重要"。
双写兜底,是告诉系统"任何一个存储层都可能失败,不要单点信任"。这些原则不是画作游戏专有的,它们适用于任何有"用户生产内容"(UGC)的游戏。自由创作世界的本质挑战,是让无限的用户创意在有限的基础设施约束下优雅地运行。
附录:关键参数速查
参数值备注单 Key 体积上限30 KBserverCloud API 限制
world_meta 体积< 2 KB背包20格 + 位置
单画作 Key 体积≈ 4.5 KB3槽 × 1.4KB + overhead
最大 Key 数(画作)≈ 606分类 × 10物品
world_meta 节流30 秒背包/位置变化
world_v1 节流60 秒地图建造变化
画作刷盘延迟30 秒最后一次保存后
全量校验周期10 分钟兜底同步
画布尺寸16×16 像素单幅
调色板大小48 色v3 编码