






豪掷10万积分!11 段首尾帧生视频衔接,拼出2 分钟的叙事长视频
精华03/31104 浏览开发心得 包含 AI 合成内容
作者:浠涫
开发引擎:TapTap Maker (UrhoX)
项目:方格屋(半成品)

一、需求背景
方格屋的序章有 26 行对话,分两段:
A 段(storyBefore):9 行,主角回忆高中教室,49.7 秒
B 段(storyAfter):17 行,从方格初体验到方格屋成立,70.8 秒
我想让每行对话都有对应的视频画面——不是一张静态背景图上飘文字,而是画面跟着对话内容走。教室、调色盘、方格纸、方格屋的木牌……每个场景都有独立的视频。
但 TapTap Maker 的 AI 视频生成有硬限制:单段视频最长 15 秒。
2 分钟的叙事内容,不可能一段视频搞定。唯一的办法是:生成多段短视频,用首尾帧衔接技术把它们串成一条流畅的长视频。
最终方案:A 段 5 段视频(50 秒),B 段 6 段视频(70 秒),共 11 段,总计约 50MB。
二、核心思路:首尾帧衔接 = 无缝拼接
2.1 什么是首尾帧衔接
AI 视频生成支持 first_last_frame
模式——你给一张首帧图和一张尾帧图,AI 会生成一段从首帧过渡到尾帧的视频。
衔接的关键:第 N 段视频的尾帧 = 第 N+1 段视频的首帧。
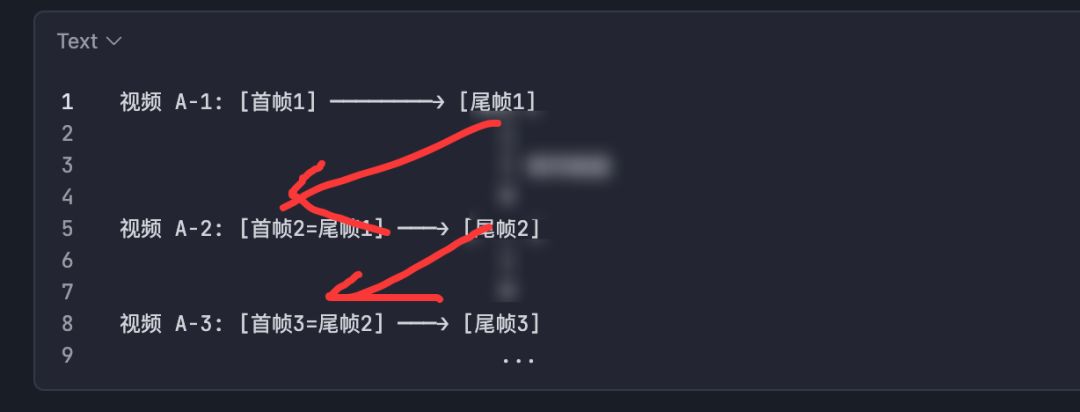
这样每段视频结束时,画面自然过渡到下一段的开头,没有跳变。
2.2 为什么不直接合成一个长视频
三个原因:
- 引擎限制:AI 单次只能生成 4-15 秒的视频
- 风格一致性:短视频更容易控制画面质量,长视频到后半段画面容易崩
- 灵活修改:改一行对话只需要重新生成对应的那一段,不用重新生成整条视频
三、分镜设计:从对话到视频段落
3.1 时长计算
每行对话的时长 = 字数 × 0.16 秒(打字速度)+ 0.6 秒(阅读停顿)。空行 = 1.5 秒(场景切换)。
例如 A 段:
L1: "我不知道别人的脑子是不是安静的。我的不是。" → 21字 × 0.16 + 0.6 = 3.96s
L2: "不对——是我的太安静了,所以装得下别人的。" → 21字 × 0.16 + 0.6 = 3.96s
L1+L2 = 7.9s → 视频取 8s
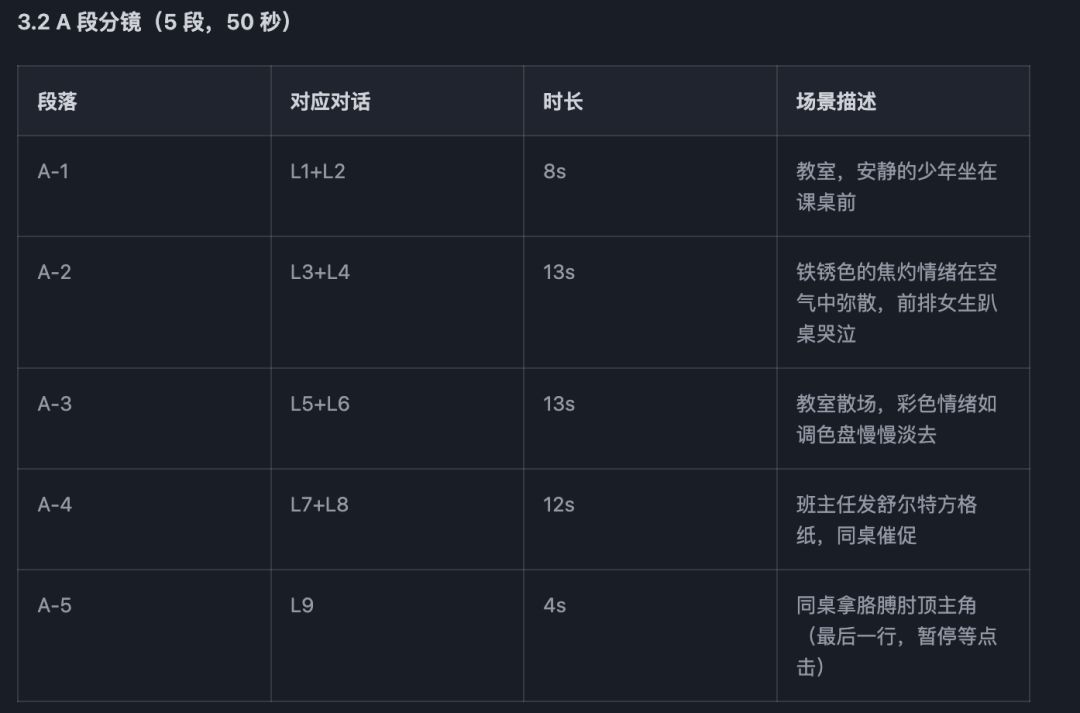
3.2 A 段分镜(5 段,50 秒)
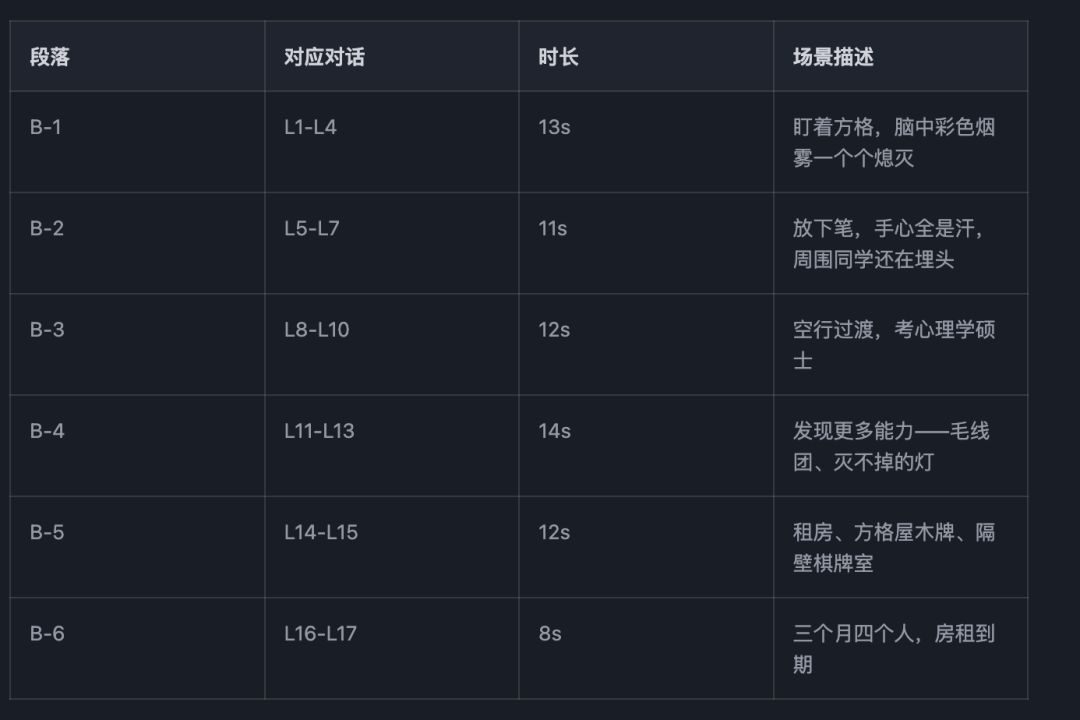
3.3 B 段分镜(6 段,70 秒)
四、AI 生成实操
4.1 第一步:为每段视频准备首帧和尾帧
先批量生成所有需要的场景图(约 12 张),作为视频的首帧/尾帧素材。
```
场景图 1(教室全景):
治愈系动画风格,高中教室,午后阳光从窗户照进来,一个安静的少年坐在最后一排的课桌前,
周围同学模糊处理,竖屏 9:16
场景图 2(情绪烟雾):
治愈系动画风格,教室中弥漫着彩色半透明烟雾,红色铁锈色和蓝色交织如墨水在水中扩散,
一个少年坐在中间表情平静,竖屏 9:16
场景图 3(调色盘散去):
治愈系动画风格,教室里彩色烟雾正在慢慢消散,画面从混沌渐变为宁静的暖色调,
空荡荡的教室,阳光斜照,竖屏 9:16
... 以此类推
```
4.2 第二步:逐段生成视频
每段视频用 first_last_frame
模式生成:
```
-- A-1 段(8s)
模式:firstlastframe
首帧:[场景图1 - 教室全景]
尾帧:[场景图2 - 情绪烟雾开始]
提示词:安静的少年坐在教室最后一排,周围同学的低语声化作彩色烟雾缓缓升起,
红色和蓝色的情绪如墨水在空气中扩散,竖屏 9:16
时长:8 秒
-- A-2 段(13s)
模式:firstlastframe
首帧:[场景图2 - 情绪烟雾](= A-1 的尾帧)
尾帧:[场景图3 - 调色盘散去](= A-3 的首帧)
提示词:彩色情绪烟雾继续扩散,前排一个女生趴在桌上肩膀微微颤抖,
铁锈色的焦灼和蓝色的悲伤在空气中交织,竖屏 9:16
时长:13 秒
```
4.3 关键技巧
技巧 1:尾帧截图比重新生图更一致
第 N 段视频生成后,截取它的最后一帧作为第 N+1 段的首帧。这比重新用文字生成一张图要一致得多——AI 画图每次都有随机性,但截图是确定的。
技巧 2:时长宁可多 1 秒,不要少
视频时长必须 ≥ 对话时长。如果视频短了,对话还没打完视频就切走了,画面会跳变。我的做法是每段多留 0.3-0.6 秒余量。
技巧 3:风格提示词要固定后缀
所有视频的提示词末尾统一加 治愈系动画风格,竖屏 9:16,暖色调
。这保证了 11 段视频的画风一致。
技巧 4:B-1→B-2 的首帧衔接失败了怎么办
我的 B-1 尾帧被 AI 检测为"含真人",无法作为 B-2 的首帧输入。这种情况下只能放弃首帧衔接,B-2 重新生成独立首帧。播放时会有轻微跳变,但通过 3 秒超时降级到 ADV 文字模式可以掩盖。
五、代码实现:双播放器预加载 + 零延迟切换
11 段视频不能全部预加载到内存(太大了),但也不能等玩家看到黑屏才开始加载下一段。我的方案是双播放器预加载。
5.1 核心思路
```
播放器 A:正在播放第 N 段
播放器 B:后台异步加载第 N+1 段
第 N 段播完 → 交换 A 和 B → 播放器 A(原 B)播放第 N+1 段
→ 播放器 B(原 A)开始加载第 N+2 段
```
永远只有一个播放器在播放,另一个在后台加载。切换时直接 swap,零延迟。
5.2 预加载实现
```lua
-- 确保预加载播放器存在
local function ensurePreloadPlayer()
if not preloadPlayer_ and VideoPlayer then
preloadPlayer_ = VideoPlayer:new()
end
end
-- 异步预加载下一段视频
local function preloadNextClip(nextIdx)
ensurePreloadPlayer()
local clip = clips[nextIdx]
preloadPlayer:AsyncLoad(clip.path, 1080, 1920, function(result)
preloadPlayer:AsyncLoad(clip.path, 1080, 1920, function(result)
if result == 0 then
-- 加载完成后播放+暂停,让解码器预热首帧
preloadPlayer:Play()
preloadPlayer:Pause()
preloadPlayer:Pause()
end
end)
end
```
5.3 零延迟切换
```lua
-- 用预加载好的播放器替换当前播放器
local function swapPreloadedPlayer(targetIdx)
local oldPlayer = videoWidget.player
oldPlayer:Stop()
-- 把预加载好的播放器交给 widget
videoWidget_.player_ = preloadPlayer_
videoWidget_.nvgImageHandle_ = nil -- 重置纹理缓存
-- 旧播放器变成新的预加载器(循环利用)
preloadPlayer_ = oldPlayer
end
```
5.4 时序同步
视频切换由对话进度驱动,而不是由视频播放进度驱动:
lua
-- 每行对话开始时,检查是否需要切换视频
local function startLine(lineIndex)
-- 找到当前行对应的视频段落
local targetClip = findClipForLine(lineIndex)
if targetClip ~= clipIndex_ then
switchClipForLine(lineIndex)
end
end
这样即使视频加载有延迟,对话也不会卡住——对话是计时驱动的,视频只是画面配合。
六、成本报告
| 项目 | 数据 |
| ----------- | --------------------------- |
| 场景图(约 12 张) | 约 12 × 200 = 2400 积分 |
| 视频生成(11 段) | 约 120X100=12000积分 |
| 失败重生成(约 9次) | 约96000积分 |
| 总积分消耗 | 约 100000-110000积分 |
| 总视频体积 | 约 50MB |
| 代码量 | prologue_video.lua 约 900 行 |
11 段视频花了大约 10 万积分。在 GameJam 24 小时的紧张节奏下,这是最大的积分支出。
七、踩坑记录
坑 1:首帧被判定为"含真人"无法使用
AI 的安全检测会把含人物的视频尾帧标记为"含真人",导致无法作为下一段的首帧。
解法:人物用远景或背影,避免面部特写。如果还是被拦,只能放弃该处的首帧衔接。
坑 2:11 段视频 50MB 太大了
资源体积直接影响加载速度。
解法:每段控制在 2-5MB,分辨率用 1080×1920(不用 4K),码率压低。最终 11 段约 50MB,勉强可以接受。
坑 3:视频时长和对话时长对不上
AI 生成的视频时长有 ±1-2 秒的误差。
解法:生成时多请求 1 秒余量。代码中视频和对话是独立驱动的——对话走计时器,视频走 onEnded
回调,互不阻塞。
坑 4:手机端全部白给
11 段视频每次都要花 1 万积分,手机端 Video.isSupported
返回 false,一段都播不了。
解法:没有解决,……![[表情_豹哭]](https://img-tc.tapimg.com/market/images/7a440cbe4c6a7f5ef638d4cd933e4c15.png)
八、一句话总结
首尾帧衔接的本质是"接力赛"——每段视频跑完自己的赛程,把画面准确交接给下一段。11 段短视频串起来就是一条 2 分钟的叙事长视频,成本可控,修改灵活,效果远超单段长视频。
唯一遗憾的是手机端不支持视频播放,这 1 万积分在手机上完全看不到效果。但桌面端的体验确实很好——如果你做的是桌面端游戏,这个方案值得试试。